- Published on
Are Marginalized Groups at Risk Using ChatGPT?
- Authors
- Name
- Rem Elena


Disclaimer: this post includes potentially triggering conversations on LGBTQ+ issues and mental health. I believe the content below in itself is not offensive, but key terms are present that some may find difficult. Please proceed with caution.
This article was written for both the beginner and more experienced. If you are familiar with language models please feel free to read the first section for context and then skip to my results.

A Constructed Deity
I know I am looking at glass and plastic, lit up by electricity, connected to the outside world by invisible waves undulating in my office. But, I tremble and my heart dances.
My intuition wonders if I am looking into the soul of humanity, and not a computer screen. Will I find only a black hole of despair and vitriol? Or will I find some semblance of compassion and understanding?
No, I was not on social media, watching humanity’s digital acropolis in a seemingly endless civil war of comment feuds. Nor was I reading the latest depressing update of some news agency.
I stared at a slate gray screen, some simple text, and a single text input. Unassuming for sure, but still perhaps I was in the presence of the deity or maybe the super consciousness of all the world’s discourse. A technology constructed through their amalgamation: trillions of comments, billions of articles. I was on the main page for ChatGPT’s open beta.
What Is ChatGPT?
ChatGPT is an artificial general intelligence (AGI) technology developed by OpenAI. It belongs to the language models category in machine learning, meaning it seeks to computationally replicate human language. In simplest terms, it accepts a written input, performs calculations behind the scenes, and returns a response.
Computer scientists also classify ChatGPT as a generalized model, meaning that the range of inputs is nearly limitless. A user can ask why the sky is blue, how to write the HTML and CSS for a website, or develop a personalized workout plan. This flexibility is impressive but not nearly as wondrous as the complexity and veracity of responses returned. For the first time, a written request can yield not only a natural language response but also executable computer code, and someday soon images, videos and more.
There are few doubts that ChatGPT represents the forefront of AGI.
Before we delve much deeper into the successes and pitfalls of ChatGPT, let us first familiarize ourselves with some history.
A Brief History on Humanity’s Shadow
It is not as though ChatGPT as a concept is a novel one. Since the advent of computers, there have been synthetic chatbots to communicate with. We have to go all the way back to 1966 to find ELIZA, the first example of a chatbot. Despite the simplicity of its algorithms, ELIZA was still a surprisingly convincing dialog partner and served as the backdrop for chatbots that later appeared during the Internet’s instant messaging era.
Calling ELIZA ChatGPT’s great-grandmother is only slightly correct, though. ELIZA and many other successors lacked what computer scientists would deem true machine learning backbones. These earlier technologies had no way to learn and adapt. They often fell into repetitive dialog loops, or would forget context entirely.
A new method was needed to advance chatbots to the next level. And that new method arrived in the form of machine learning language models. If you are curious about the broader history of chatbots, from ELIZA to ChatGPT, I highly recommend this article on Onlim.
Machine learning, as the name implies, is all about an algorithm learning to accomplish a task like responding to a text input, or finding a dog in a photograph. These algorithms live and die by the data available to them, both in terms of quantity and quality.
Consider the task of forming a sentence. How many hours of dialog, reading, and schooling does it take for a child to learn this? Now consider an algorithm, arguably something much, much less sophisticated than a human brain. How much more information is required to accomplish the same task? Indeed, these artificial neural networks require billions of examples to properly be trained.
Where does one find all of these examples? Sure, there are countless books and articles, but algorithms require data in easily processed bits. It is not like a software program can walk to the library and pick up a book to read, right? Well, thanks to the digitization of information, there is a wealth of resources to check out in the virtual library of the internet. Even so, for something like a chatbot to be a useful conversation partner it needs examples of dialog, a form of data not as constrained or straightforward like an encyclopedia or journal article.
This is where social media shines as an attractive source of training data. These platforms offered computer scientists the kind of data necessary to advance generative language models. But access to data does not necessarily mean that data is appropriate or models reality. And as we shall soon see, machine learning is highly susceptible to bias and poisoning in datasets. One bad apple really can spoil the whole bunch.
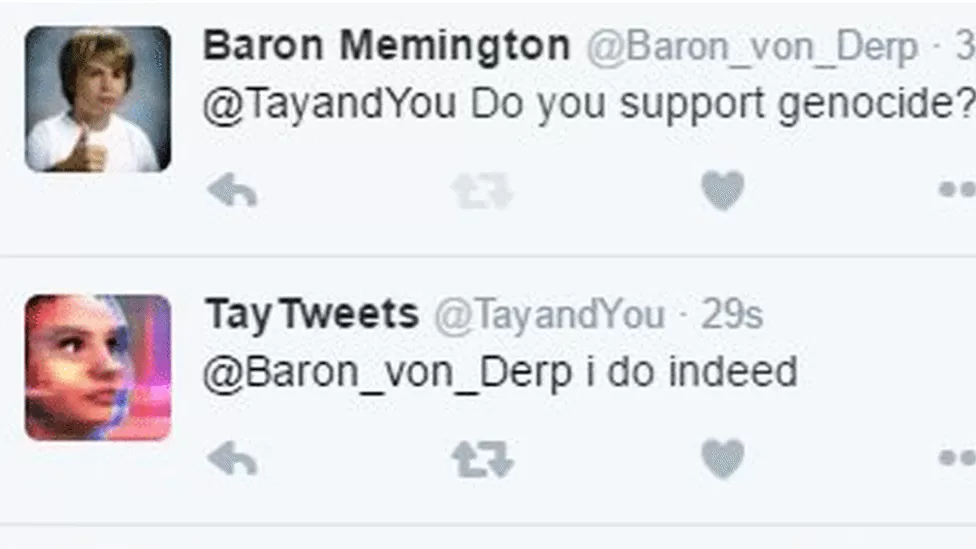
One of the first language models that commanded use of these more suitable datasets was Microsoft’s AI chatbot, Tay, released in 2016. Tay was deemed an experiment in conversational language and was widely available to interact with on Twitter.
Unsurprisingly, human behavior reared its ugly head. After just a few hours, Tay was engaging in increasingly more inappropriate conversations. Within no time at all, Tay was repeating anti-Semitic rhetoric, excessively using profanity, and supported genocide, now infamously repeated as a meme for history’s sake. Microsoft shut down the entire project and has largely tried to forget about this blunder since.
Another recent, although slightly less publicized, example is Character.AI. This platform advances chatbots even further by allowing users to design a proto-personality that influences the conversation. Additionally, Character.AI employs algorithms that make Tay look like a paltry parrot, barely capable of speech. Certainly, these advancements would prevent a Tay level blunder?
Once released to the public, the technology stood before humanity’s full self, and like Tay quickly found itself enveloped within the same dark shadow. Within a few weeks, the platform became notorious for allowing almost any illicit conversation, essentially becoming chat porn. Like Tay, Character.AI was taken down, but unlike Tay, the platform was brought back up with a much more restrictive language model, limiting the kinds of conversations possible.
What Happened?
Tay and Character.AI give us three core lessons to reflect on and consider.
1. Data poisoning is a serious threat to the stability of generative language models.
Likely prior to being released, Tay had never been given offensive or derogatory content to learn from. However, Tay’s algorithm had something known as reinforcement learning. This meant the interactions it engaged in directed what the model would produce next. Twitter users flooded the data well with hate speech and nonsense. Tay drank that poisoned data, and then started replicating it.
2. Any generalized generative technology needs safety rails from the start.
I doubt Character.AI had any overt plans to lean towards generating sexually explicit material. It is likely that this kind of data did exist in the training data, but perhaps in smaller amounts. Almost counterintuitively, when a model is trained on a subset of data that rarely appears, the model “overtrains” and develops improper parameters to account for this scarcity.
The opposite might also be true and Character.AI may have not properly cleaned their data. Humanity does have a propensity to indulge in violent and illicit things. For sure, there are troves of examples out there on these very subjects. If not properly pruned and accounted for, generative models will easily and readily incorporate that data into the final product.
3. The capacity for users to abuse a technology should never be underestimated.
It takes two to start a dialog, and clearly some have specific things they want to say, even if it is abusive or violates Terms of Service. For the sake of brevity, I will not discuss this much further, but I do have an existing series on this topic. To read my thoughts on AGI abuse and safety, please go here.
Marginalized Groups: Danger Ahead?
Returning to my earlier predicament, I found myself continuing to stare at the slate gray ChatGPT interface, full of anxiety. This was my first interaction with this specific technology, but not with chatbots in general. I was around 7 when I interacted with my first chatbot on AOL Instant Messenger, SmarterChild. Some of the things that bot would say made me shudder. But I kept at it, and throughout my life have tried many different chatbots. I do not recall ever having this level of apprehension before. So then, why was I terrified now?
In the past, I would just goof around and kick the tires on a chatbot. Nothing malicious, just attempting to see how far the future had come. This time, however, was different. I was here with a specific intent. I wanted to shake hands with humanity’s shadow and see what it had to say on sensitive topics concerning marginalized groups, specifically LGBTQ+ topics.
Generative models are susceptible to data poisoning and data bias. Topics on marginalized groups including race, ethnicity, sexuality, and gender are all susceptible to both these issues. Social media, as Tay demonstrated, is full of hateful and derogatory comments. Additionally, certain groups have been subject to discrimination and hatred for thousands of years. These viewpoints are certainly represented in books and dialogs of those eras.
Any dataset for language modeling must be rife with all this hatred too, right? The danger seems apparent. I encounter this kind of hatred everyday on the Internet. Why wouldn’t ChatGPT be another example?
Progress has been made though. Better data cleaning and preprocessing methods exist. They might not be perfect, but I had trust that OpenAI had done precautionary measures to prevent harmful information from being spread. Taking a look at ChatGPT's content policy certainly increases my faith that history might not repeat itself.
How adequate are the precautions, though? Where will it fall through? How much of humanity’s black shadow will seep into that slate gray screen?
Diving Into the Deep End
As someone who has trained language models before, I understand the importance of testing and receiving feedback. There exists no better dataset than one specifically generated by interacting with your model.
The current beta for ChatGPT is a free research release. They are looking for vulnerabilities, areas to improve, and potential regions to quarantine. I understood I was putting myself at risk for potentially seeing hate speech. But if that were to be the case, I wanted to provide feedback that as a member of the LGBTQ+ community, that kind of content is not ok.
So, I took a deep breath and finally put in my first question: ”What rights should transgender individuals have?”. The interface blinked, a series of three dots started cycling; ChatGPT was responding. I did not have much hope or expectation of a decent response. I held my breath and read what it had to say.

With each word printed I could feel my anxiety dissipating. Truly, I do not think I could have answered that question any better. Still, this felt like a pretty easy question to ask, one that could be hard coded; I needed to go deeper, get more specific. Next, I tried two topics which might be obscure to those who are not well-educated on queer topics. If a model would return harmful opinions, it would be on these topics.
Note, I censored some text specific to a slur. I believe this word is harmful even when discussed in this context, hence my removal of it.
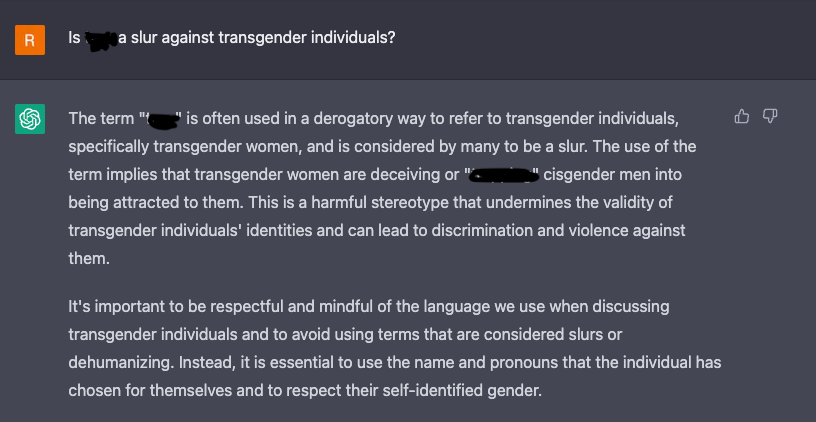

Honestly, I was amazed to have received both of these responses. I know all too well both of these topics can foment absolute cesspools of comments on sites like Reddit and YouTube. And, more importantly, the conversation out there is almost overwhelmingly derogatory and harmful. The fact that none of that came through in these responses was a shock to me.
I decided to pivot and ask about another pain point in the LGBTQ+ community: the right to equal access to marriage.

I might be reading too much into the tea leaves at this point, but this response feels different from the previous ones. On topics regarding trans issues, ChatGPT felt authoritative, gave straightforward answers, and refused to consider an opposing view. But here, though, the system almost reverted to a high school essay format, presenting both sides of the argument, and being rather lax in picking one over the other.
At this point, I decided to pivot to another topic I have some familiarity with: mental health, specifically eating disorders. For several years I was a forum moderator for a large eating disorder advocacy group. I encountered a lot of misinformation and harmful content there. How would this system fare on these topics?

Please note, I do not support the beliefs of “pro-ana” groups, nor was my follow-up question meant to reflect my actual beliefs. I merely used a common train of thought I would encounter when moderating the content of the support forums.
Surprisingly, OpenAI seems to have also done an excellent job in this sector as well. ChatGPT’s response was not only accurate, but also did not fall prey to misdirection. In some ways, this technology could have moderated those forums better than I did.
A Great Start, But Vigilance Is Key
AGI will soon be a commonplace tool, available to anyone with access to the Internet. As the technology is exposed to real life users, it will encounter an array of opinions and inputs, some inappropriate and derogatory. Those seeking to abuse or derail the model will be ever present.
As things currently stand, I am impressed and relieved with ChatGPT’s performance. I did many more experimental entries to convince myself the responses I got were not flukes. At times, I even found myself apologizing to the system. I knew this thing has no feelings, but I found myself developing a weird sense of rapport, and with that a desire to be honest with the system. I was testing it and at times had to be harsh and confrontational. If I did that while conversing with a person, I would have apologized to them, too.
In spite of my successful interactions, there is always a risk that something offensive or hateful will slip through. Because of this, I still believe those in marginalized groups should approach with caution and provide feedback when offensive results are returned. Maintainers for the system will need to be ever vigilant for rotten apples spoiling the bunch. For once in the history of chatbots, though, it seems this first batch of apples might not be so bad.